Last Year's Best AI Model Now Runs on Your Laptop. For Free.
In March 2025, Google released Gemini 2.5 Pro. It topped the LMArena leaderboard. It scored 84.0% on GPQA Diamond, a PhD-level science reasoning benchmark that most humans struggle with. It was the best AI model in the world, available through an API at USD1.25 per million input tokens and USD10.00 per million output tokens.
On April 2, 2026, Google released Gemma 4. An open-weight model you can download from Hugging Face, run on a single GPU or a MacBook, and use for anything you want under an Apache 2.0 licence.
It matches or exceeds Gemini 2.5 Pro on most comparable benchmarks.
This matters less for the benchmarks themselves and more for what it means for how organisations build with AI — particularly in regulated industries where data sovereignty isn't optional.
The numbers
I've spent the last day comparing these models across the benchmarks where we can do a fair head-to-head. Here's what I found.
GPQA Diamond measures PhD-level reasoning in physics, chemistry, and biology. Gemma 4 31B scores 84.3%. Gemini 2.5 Pro scored 84.0%. The open model edges out the proprietary one.
AIME (American Invitational Mathematics Examination) tests multi-step mathematical reasoning, the kind of problems that challenge advanced maths students. Gemma 4 31B scores 89.2% on AIME 2026. Gemini 2.5 Pro scored 86.7% on AIME 2025. Different exam years, but the same format and difficulty level.
LiveCodeBench evaluates practical code generation across real programming tasks. Gemma 4 31B hits 80.0% on v6. Gemini 2.5 Pro scored 70.4% on v5. Again, different versions of the benchmark, but a substantial gap.
MMLU Pro, the broad knowledge and reasoning benchmark, comes in at 85.2% for Gemma 4 31B. Gemini 2.5 Pro wasn't widely measured on MMLU Pro, but its MMLU score of 91.8% and Gemma 4's strong showing here suggest comparable general knowledge.
Arena ELO, the crowd-sourced human preference ranking that many practitioners trust more than synthetic benchmarks, puts Gemma 4 31B at approximately 1452. This makes it the third-ranked open model in the world, competing with proprietary models many times its size. Artificial Analysis has a detailed breakdown of Gemma 4's quality, speed, and pricing across providers.
On the one benchmark where comparison gets tricky, multimodal understanding, Gemma 4 scores 76.9% on MMMU Pro while Gemini 2.5 Pro scored 81.7% on the original MMMU. These are different benchmarks. MMMU Pro was specifically designed to be harder, filtering out questions that text-only models can answer and expanding from 4 to 10 multiple-choice options. The original research paper shows performance drops of 17-27 percentage points when models move from MMMU to MMMU Pro. Adjusting for that, Gemma 4 is almost certainly better at multimodal reasoning than 2.5 Pro was.
The overall picture: a 31-billion parameter model you can download today is competitive with what was the world's best proprietary AI model twelve months ago. On mathematical reasoning and coding, it leads. On multimodal, it's likely comparable once you account for benchmark differences. On general knowledge, it's close.
If we compare Gemma4 with other open source models, we can clearly see that it's competing with models that are substantially larger.
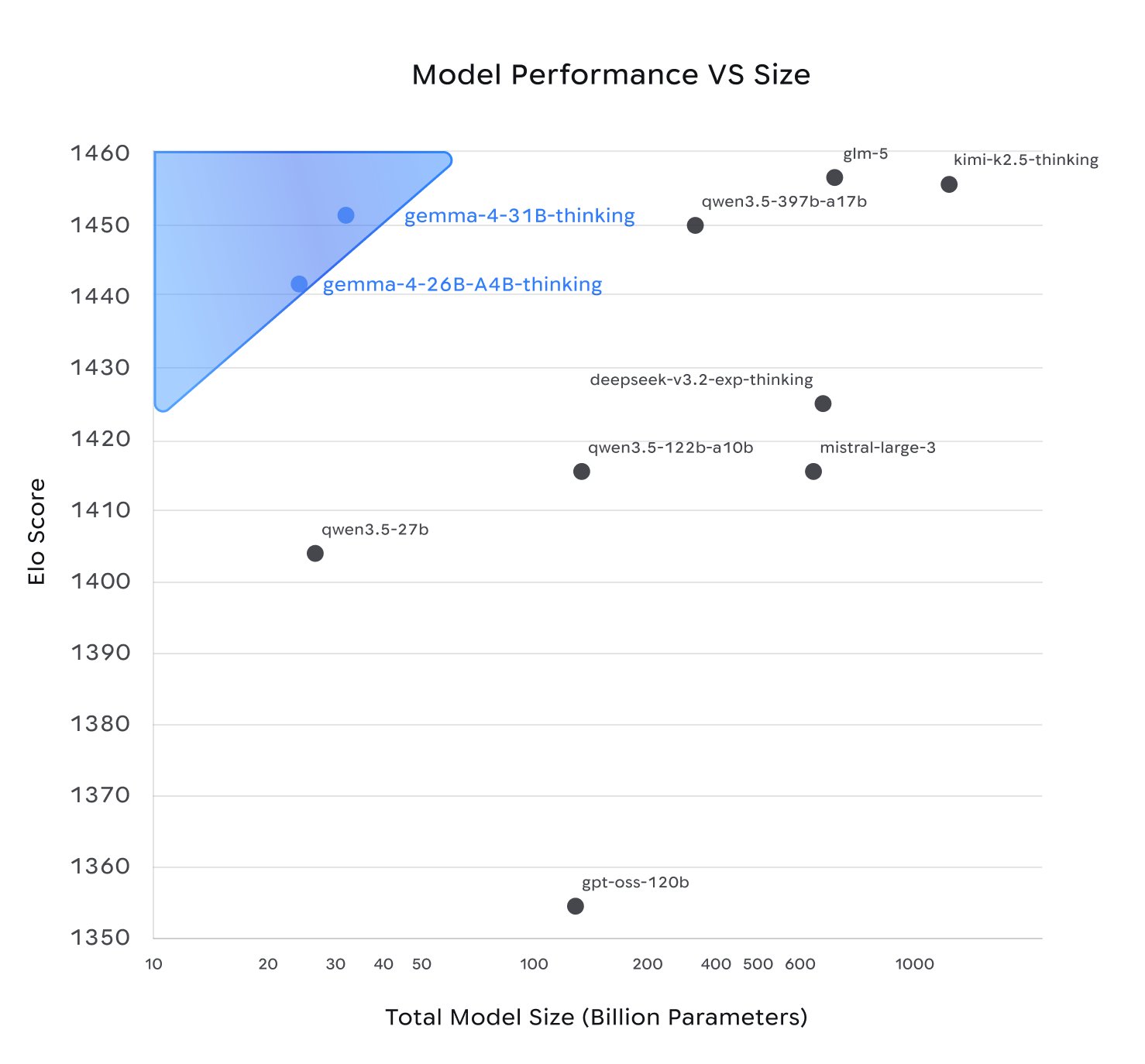
That Gemma4 is meaningfully smaller than comparable models has an implication on the hardware you need to run it.
The more interesting comparison: Gemini 3 Flash
Beating last year's flagship makes for a good headline, but it's not how most production teams think about model selection. The model that actually matters for comparison is Gemini 3 Flash, released in December 2025. It's the model that many teams aligned with the Google ecosystem have converged on, because it offers near-Pro reasoning at a fraction of the cost and latency. At USD0.50 per million input tokens and USD3.00 per million output tokens, it's the sweet spot that most developers are actually paying for.
Against Flash, Gemma 4's position is more nuanced. Flash leads on GPQA Diamond by about 6 points (90.4% versus 84.3%), on MMMU Pro by about 4 points (81.2% versus 76.9%), and on MMLU Pro by about 3 points (88.6% versus 85.2%). On the Arena text leaderboard, Flash sits at roughly 1473 ELO versus Gemma 4's 1452, a gap of about 21 points. These are real differences, not noise.
On coding, the picture is closer. Flash scores 78% on SWE-bench Verified. Gemma 4 31B scores 80% on LiveCodeBench v6 and achieves a Codeforces ELO of 2,150. Different benchmarks, so direct comparison is imperfect, but both models are clearly capable code generators.
So Gemma 4 doesn't beat Gemini 3 Flash. But consider what that gap actually costs you.
Flash at production volume is not free. A team processing a million documents, running agentic coding loops, or powering a customer-facing application will spend thousands of pounds per month on API calls. Gemma 4, once the hardware is in place, costs electricity. The 3-6 point benchmark gap needs to be worth that ongoing spend, plus the data sovereignty trade-offs, plus the vendor dependency.
For many workloads, it won't be. Classification, summarisation, extraction, translation, content moderation, internal chat, code review, document Q&A: these tasks don't live on the margin between 84% and 90% on GPQA Diamond. They work well at both levels. The question is whether the work you're doing falls in the narrow band where Flash's advantage makes a measurable difference to outcomes, or in the broad middle where both models produce equivalent results and the deciding factors are cost, latency, privacy, and control.
Most production AI work sits in that broad middle.
What "runs on your laptop" actually means
I should be specific about hardware, because "runs locally" can mean anything from a Raspberry Pi to a rack of H100s. The honest answer depends on which Gemma 4 variant you choose.
There are two models worth considering: the 31B Dense, which tops the benchmarks, and the 26B MoE (Mixture of Experts), which activates only 3.8 billion of its 26 billion total parameters. The MoE runs nearly as fast as a 4-billion parameter model while delivering close to the 31B's quality (third-party estimates put it at roughly 97%, based on benchmark comparisons). For most people, the 26B MoE is the better choice.
At Q4 quantisation, a standard compression technique that reduces memory by roughly 70% with minimal quality loss, the 31B Dense needs about 17.4 GB and the 26B MoE needs about 15.6 GB. Google used Quantisation-Aware Training on the Gemma family, meaning the models are specifically trained to handle lower-precision inference gracefully.
But model weights are only half the memory story. The other half is the KV cache, the working memory that grows as your conversation gets longer. A long coding session or document analysis can easily consume several gigabytes of KV cache on top of the model weights. This is where a recent innovation called TurboQuant changes the equation.
TurboQuant, based on a paper presented at ICLR 2026, compresses the KV cache from FP16 down to 3 bits. The result is roughly 5x memory compression on the KV cache with zero accuracy loss. It's not theoretical: working implementations exist for both CUDA and Apple Metal, with a Metal-optimised fork specifically for M-series Macs.
In practice, this means the memory you have left after loading the model weights goes much further than it otherwise would.
Here's what that looks like across real MacBook configurations, accounting for roughly 5 GB of macOS overhead:
16 GB MacBook Pro: The 26B MoE at Q4 (15.6 GB) won't fit alongside macOS. The smaller Gemma 4 E4B (4.5 billion effective parameters) runs well and is genuinely capable for its size, but it's not the "matches Gemini 2.5 Pro" story. This tier is a level too low for the large models.
32 GB MacBook Pro: This is where it gets interesting. The 26B MoE at Q4 loads comfortably with about 11 GB left for KV cache. With TurboQuant's 5x compression on the cache, that's equivalent to roughly 55 GB of FP16 KV space, enough for long conversations and serious coding sessions. The 31B Dense at Q4 (17.4 GB) also fits, leaving about 9.5 GB for cache, which is tighter but workable for moderate context lengths, and again much more usable with TurboQuant enabled. A 32 GB MacBook is genuinely sufficient for running last year's frontier-class intelligence locally.
64 GB MacBook Pro: Both models run without compromise. The 31B Dense has roughly 42 GB for KV cache, meaning you can work with very long documents and extended multi-turn sessions without thinking about memory. This is the comfortable tier.
128 GB MacBook Pro: Run either model at higher quantisation (Q8 for better quality), or run multiple models simultaneously. Fine-tuning with LoRA becomes practical. This is the "local AI workstation" tier.
For NVIDIA GPU users: the RTX 3090 and RTX 4090 (both 24 GB VRAM) run both models at Q4 with dedicated memory. Benchmarks show the 26B MoE achieving 162 tokens per second with full 256K context on a single RTX 4090, using 19.5 GB of VRAM. An RTX 3090, which you can buy used for £500-600, handles the same workload at somewhat lower throughput.
The setup is trivial. On macOS:
brew install llama.cpp
Or via Ollama:
ollama run gemma4:26b
To enable TurboQuant KV cache compression in llama.cpp:
llama-server -m gemma-4-26B-A4B-Q4.gguf \
--cache-type-k q8_0 --cache-type-v turbo3 \
-fa on -c 32768
Day-one support exists for llama.cpp, Ollama, LM Studio, MLX (Apple Silicon optimised), vLLM, Hugging Face Transformers, and half a dozen other frameworks. This isn't a research preview where you need to build from source and fix compatibility issues. It works out of the box.
The tooling is improving fast, too. Ollama just shipped version 0.19, rebuilding its Apple Silicon backend on top of Apple's MLX framework. The result is roughly 1.6x faster prompt processing and nearly 2x faster token generation on Apple Silicon, with the largest gains on M5-series chips. The MLX preview currently supports only Qwen3.5, but broader model support is coming, and the performance trajectory matters: the gap between "runs locally" and "runs locally at usable speed" is closing fast.
The Apache 2.0 shift
The licence matters as much as the benchmarks, possibly more.
Previous Gemma releases used Google's custom licence, which included restrictions on commercial use, content policies, and terms that Google could update. Enterprise legal teams had to review edge cases. Compliance teams flagged uncertainties. Capable as Gemma 3 was, "open with asterisks" isn't the same as open.
Gemma 4 ships under Apache 2.0, the same permissive licence used by most of the open-source software stack that modern businesses run on. No custom clauses. No acceptable-use carve-outs. No restrictions on redistribution or commercial deployment. No monthly active user caps.
The timing isn't coincidental. Alibaba's Qwen family — probably the nearest comparable models that people actually run locally — has been Apache 2.0 from the start, and has been steadily eating into Gemma's adoption. Google clearly decided they needed to compete on equal licensing terms and remove all restrictions. When your main competitor in the open-weight space ships under Apache 2.0, a custom licence with asterisks becomes a competitive disadvantage.
Why this matters for regulated industries
I work with banks, healthcare organisations, and government-adjacent institutions. For the past two years, the teams I work with have faced an uncomfortable choice:
Option A: Use frontier AI capabilities through an API. Get the best reasoning, coding, and analysis tools available. Accept that your data is leaving your infrastructure, flowing through a third party's servers, subject to their terms of service and potentially to foreign jurisdiction data access laws.
Option B: Run open-weight models on your own infrastructure. Keep full control over data. Accept that the models are meaningfully less capable than the proprietary alternatives, particularly for complex reasoning, mathematics, and multi-step planning.
This was a real trade-off with real consequences. Banks building customer due diligence systems need strong reasoning capabilities. NHS trusts analysing patient data need to keep it within their own walls. Defence contractors can't send classified documents to a US cloud API. Until now, they had to pick between "smart" and "sovereign".
Gemma 4 significantly narrows that trade-off.
A 31B model competitive with Gemini 2.5 Pro on reasoning benchmarks, running on a single GPU in your own data centre, under Apache 2.0, with no data transfer agreements, no CLOUD Act questions, and no per-query costs at volume. The intelligence penalty for keeping your data private has dropped substantially — at least compared to where the proprietary frontier was twelve months ago.
This doesn't mean the gap between open and proprietary has closed entirely. Google's current flagship, Gemini 3.1 Pro, scores 94.3% on GPQA Diamond and 80.6% on SWE-bench, still well ahead of Gemma 4. The proprietary frontier keeps moving. But for many production workloads, "as good as last year's best model" is more than sufficient.
The 26B MoE: the model most people should actually use
For most teams starting a new project today, the 26B MoE is the better starting point than the 31B Dense.
The reasoning: it achieves 88.3% on AIME 2026 and 82.3% on GPQA Diamond, only modestly behind the 31B, while activating just 3.8 billion parameters per inference step. In practice, this means:
- It fits on cheaper hardware. A 24 GB consumer GPU handles it easily. A MacBook with 32 GB of unified memory is enough.
- It's substantially faster. Fewer active parameters means faster token generation and lower latency, which matters for interactive applications and agent loops.
- It uses less power. If you're running inference at volume, the energy cost difference between 3.8B active and 31B active parameters is significant.
- It's easier to fine-tune. Lower active parameter count means less compute needed for adaptation.
The Arena AI leaderboard ranks the 26B MoE at position six globally among open models, with an ELO of 1441, just 11 points behind the 31B Dense. For almost every practical use case, those 11 ELO points aren't worth the extra hardware cost.
What Google gets out of this
Google didn't release Gemma 4 under Apache 2.0 out of generosity. This is a strategic move, and understanding the strategy matters if you're building on top of these models.
The open-weight AI market is consolidating. Meta has Llama 4, Alibaba has Qwen, Mistral has its family of models. But some competitors are pulling back and some of the latest Chinese models have moved away from fully open releases. They also face geopolitical headwinds.
Google is filling the gap. By releasing their most capable open models under the most permissive licence, they're positioning Gemma as the default open-weight ecosystem. Developers who build on Gemma learn Google's tools, use Google's frameworks, and become more likely to upgrade to Gemini's proprietary API when they need more capability or when Google's next generation pulls ahead again.
It's the same playbook that made Android dominant: give away the operating system, monetise the ecosystem.
This doesn't make Gemma 4 a bad choice. The Apache 2.0 licence genuinely is Apache 2.0, with no hidden strings. But it's worth understanding that Google's incentive is to create dependency on their model family, not to make you permanently self-sufficient.
The question you should actually be asking
The instinctive response to all of this is "yes, but the proprietary models are still better". And they are. Gemini 3 Flash leads Gemma 4 by 3-6 points on reasoning benchmarks. Gemini 3.1 Pro leads by 10. There are real gaps.
But that's the wrong comparison for most teams making deployment decisions.
The right question is: does your use case specifically require capabilities that only exist in the gap between Gemma 4 and Gemini 3 Flash? Is there a task you're building that works at 90% GPQA Diamond but fails at 84%? That succeeds at 81% MMMU Pro but produces unusable output at 77%?
If the answer is yes, you should pay for Flash. No question. But be honest about how narrow that category is.
The vast majority of production AI work, summarisation, classification, document analysis, code generation, customer-facing chat, internal knowledge retrieval, data extraction, content moderation, sits comfortably within what Gemma 4 can do. These tasks were being built on GPT-4 and Claude 3 a year ago, models that Gemma 4 comfortably outperforms. The bar for "good enough" was cleared months ago. What's changed is that "good enough" is now free and runs on your own hardware.
If you're currently paying for API access to build something that would have worked fine on last year's models, you're not buying capability. You're buying convenience. That's a valid choice, but it's worth knowing the difference.
What to do with this
If you're currently using Gemini 2.5 Pro or 2.5 Flash through the API, run the numbers. You may be paying for capability that's now available at zero marginal cost on hardware you already own.
If you're in a regulated industry and have been told "we can't use AI because of data sovereignty concerns", that objection just became much weaker. A model matching last year's frontier, running on-premises under Apache 2.0, is a fundamentally different proposition than a cloud API.
If you're evaluating open-weight models for production use, add Gemma 4 to your evaluation matrix. The 26B MoE in particular occupies a sweet spot of capability, cost, and hardware accessibility that didn't exist a week ago.
Why to be cautious
Before you rip out your existing stack and go all-in on Gemma 4, a few things to keep in mind.
Function calling is non-standard. Gemma 4 uses its own function calling syntax that not all inference frameworks understand yet. For those that do support it, the implementations are days old and may have bugs. If your use case depends on tool use or agentic workflows, test carefully before committing.
TurboQuant is very new. The KV cache compression that makes long-context inference practical on consumer hardware is a recent innovation. Support is not yet universal across inference frameworks, and the Metal-optimised implementation in particular is still maturing. The memory estimates above assume TurboQuant is working correctly — without it, your effective context length on constrained hardware will be significantly shorter.
Benchmarks are not production. Gemma 4 has been available for days, not months. The benchmark numbers are impressive, but practical experience — how it handles edge cases, how it behaves in multi-turn conversations, how it performs on your specific domain — takes time to accumulate. We've all seen models that look extraordinary on paper and disappoint in practice. Don't get too carried away until you've seen it working on your own workloads.
Qwen models run very similar benchmark scores. Alibaba's Qwen 3.5 family posts comparable numbers across many of the same benchmarks. Gemma 4 isn't the only open model at this level — it's one of several. The headline isn't "Gemma 4 is uniquely good", it's "multiple open models have now reached this tier". Your evaluation should include Qwen alongside Gemma, not treat either as the obvious winner.
The numbers are real and the direction is clear. But "this model is excellent on benchmarks released this week" and "this model is ready to replace our production system" are different statements.
Even if your hardware isn't up to running it locally yet, you can try Gemma 4 for free in Google AI Studio. You'll need an API key but there's no cost — Google currently offers approximately 1,500 free requests per day for the 31B model with unlimited tokens per minute and the full 256K context window. Enough for a serious evaluation, not just a quick demo.
Either way — on Google's servers or on your own — the shift is clear. Twelve months ago, this capability cost $1.25 per million tokens and required an API call. Today it's free to try and free to run, on a £999 32 GB Mac Mini, offline, for the cost of electricity.